Dedecms织梦采集功能的使用方法-不含分页的普通文章(一)
前言:这篇文章是为了初次接触Dedecms采集功能的朋友所写的。所选取的目标站点为文章内容页面不含有分页的Dedecms官方网站的dreameaver栏目文章,通过图文并茂的形式,详细地介绍了如何创建一个基本的采集规则。本文共分为三节:第一节,主要是介绍如何进入采集界面和新增采集节点中的第一步:设置基本信息及网址索引页规则;第二节,主要是介绍新增采集节点中的第二步:设置字段获取规则;第三节,主要是介绍如何采集指定节点和如何导出采集内容。下面进入第一节。
1.1进入采集节点管理界面
如(图1)所示,在后台管理界面的主菜单中单击“采集”,然后单击“采集节点管理”,即可进入采集节点管理界面,如(图2)所示。
( )
图1-后台管理界面

( )
图2-采集节点管理界面
1.2. 增加新节点
在采集节点管理界面中,单击左下角的“增加新节点”或者右上角的“添加新节点”(如图2),都可进入“选择内容模型”界面,如(图3)所示,

( )
图3-选择内容模型界面
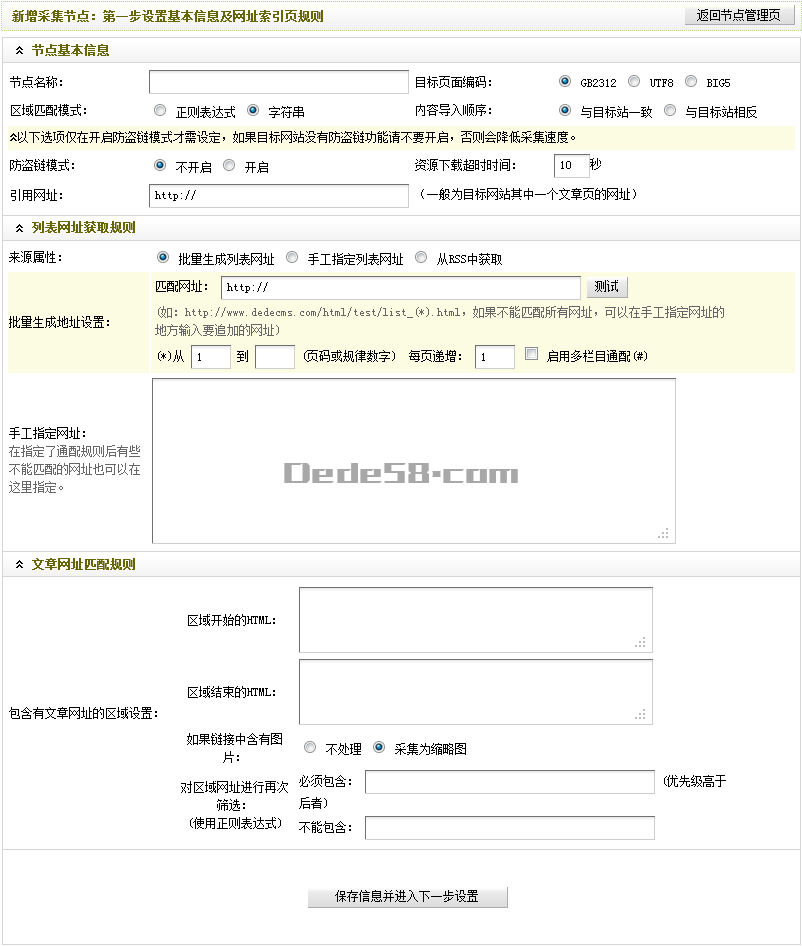
在“选择内容模型”界面的下拉列表框中,有“普通文章”和“图片集”可供选择。根据被采集页面的类型,选择相应的内容模型。本文这里选择“普通文章”,单击确定后,便可进入“新增采集节点:第一步设置基本信息及网址索引页规则”界面,如(图4)所示,
( )
图4-新增采集节点:第一步设置基本信息及网址索引页规则



