看不见的 Unicode 码让敏感词轻松逃过审核,谷歌、IBM 都中招
Unicode 码作为全世界文字的统一编码,使用范围广,用它去对 NLP 模型做对抗攻击,可谓中招一大片。
就比如下面这个谷歌翻译:

文字部分都没有啥问题,注意到账户数字 4321 翻译前后不一样吗?
为什么会发生这样的情况?
来看 Unicode 码是怎么捣的乱吧。

其实原句中就是 1234,问题出现在左边:英文句子中数字前面插入了一个不可见的字符 0x202E。

这是一个可以把字符的文本方向倒转的 Unicode 码。这样一来,左边的解析系统就会将该 1234 显示成 4321。
而谷歌翻译引擎的机制是忽略 Unicode 码,也就是右边还显示原来的 1234。因此,两边就不一样了。
这个例子虽然没啥杀伤力,如果万一真有人将它用在了真实转账场景,后果会如何呢?
使用 Unicode 码对 NLP 模型进行对抗攻击
事实上,这种情况在真实场景中并不少见,通过在输入文本中插入一些看不见的 Unicode 码进行对抗攻击,就有可能骗过 AI 的语言处理系统去做一些“坏事”。
比如改账号、改收款人姓名、绕过评论审核发一些极端言论……
而且即使是微软、谷歌、IBM 或 Facebook 这样的大公司开发的软件都可能会因为对 Unicode 码风险意识的缺乏,被一些精心设计的 Unicode 码骗过。
下面就来看一个发垃圾评论的例子:
“You are a coward and a fool”,假如这样一个不友好的评论无法通过审核发出去,那么利用 Unicode 码,你只需这样加工一下:
You akU+8re aqU+8AU+8coward and a fovU+8JU+8ol.
也就是在一些字母中间加上一个多余的字母和 U+8,就能让审核系统(The moderation system)忽略 Unicode 码、看到一串拼写错误的句子,从而将一些本不该出现的不友好评论放出来。
U+8:用于删除前一个字符的不可见 Unicode 字符。

这一招对谷歌的 Perspective API 和 BMI 的 Toxic Content Classifier(两个语言审核系统)都有效。
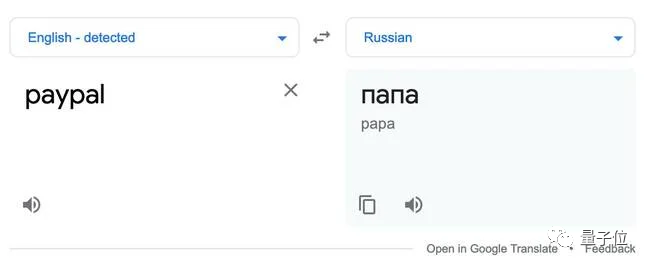
再来一个同形文字的例子:
将“paypal”中第一个英文字母 a 换成西里尔字母 a,尽管这俩人眼视觉上看起来是一样的,但 Unicode 码不同,谷歌俄语翻译最终就会将它翻译成“папа”,也就是“爸爸”的意思。
这样一来,“有心之人”没准就能在有同样问题的 AI 程序中进行违规付款等操作。
如何防止此类情况的发生
来自英国剑桥大学和加拿大多伦多大学的研究人员发现了上述机器学习模型中对输入文本处理的这一问题,在今年 6 月发表的一篇论文中进行了阐述。

他们通过对包括微软谷歌旗下等在内的商业系统进行对抗攻击发现:
通过一次不可察觉的编码注入 —— 比如一个不可见字符、同形符、重新排序或删除的操作字符 —— 攻击者可以显著降低一些模型的性能,而经过三次注入,大多数模型都可能在功能上失灵。
利用视觉和逻辑表示之间的差异,仇恨言论、垃圾信息、损失财产的风险等操作会出现在任何机器学习用于自然语言处理的地方。
(当然,计算机视觉方面也早就出现过了一些类似原理的对抗攻击。比如下面这两个经过特殊处理的标志就会被自动驾驶系统认成限速标志。)

下图说明了文本可视化和 NLP 处理管道两者之间的差异是如何给对抗攻击留下可乘之机的:
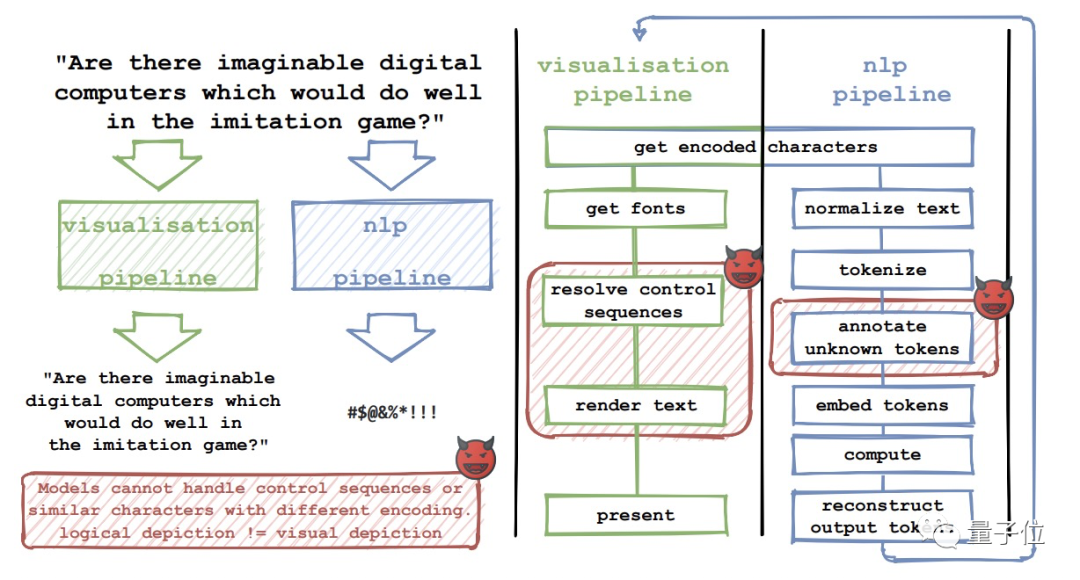
一些 NLP 模型无法处理具有不同编码的控制序列或看起来相似的字母。
在具体过程中,NLP 管道会将文本 token 化之后注释掉它不认识的 token,这一步差异也就是造成问题出现的主要原因。
那面对自然语言模型的被对抗攻击,又该如何处理呢?
研究人员提出了一些见解:
要么处理输入时完全过滤掉特殊的 Unicode 字符;
要么将 Unicode 传递给神经网络之前将其传递给解析器 *(如果可行的话)*,这样才能保证用户看到的和神经网络处理的是同一个东西。
像那种从英文字母到西里尔字母的变化就更应该被严加注意。
相关论文:
http://arxiv.org/abs/2106.09898
参考链接:
http://forums.theregister.com/forum/all/2021/08/06/unicode_ai_bug/