苹果推出图片翻译功能,能取代专业翻译软件吗
此前 iOS15 系统更新,有一个功能引发了不小的关注,那就是内置图片翻译。用户可以直接选择照片中要翻译的文本,查看翻译结果。据说苹果还更新了翻译模型,提升了翻译效果。
这就刺激了,如果说几年前神经机器翻译的出现,是许多人类翻译的噩梦,那这个系统内置翻译图片功能的推出,大概能让不少专业翻译软件睡不着觉吧。
就拿我这种需要经常阅读英文资讯的人来说,时常遇到 pdf 文献、图片类内容,需要第三方软件拍照识别后进行翻译。如果 iOS15 直接可以识别图片,不就省略了几个步骤吗?简直懒人福音。
那么问题来了,翻译好不好,重点在“疗效”,iOS15 的图片翻译能力已经强大到能替代专业翻译软件了吗?要知道,信达雅的中文表达一直是 NLP 领域的难题,一家带着硅谷基因的科技公司,真能完成地道的中英互译?
本着实践出真知的态度,我们准备了多道考题,并选取了口碑和用户数都相对突出的有道词典 App 来参与横向评测,以此来摸索 iOS15 图片翻译的真实水平。
真心话与大冒险:图片翻译三步曲
针对翻译功能的专业评测有不少,各种指标诸如短中长句都有详细的评测标准与规范,不过作为普通用户,我们决定从大家日常使用图片翻译的具体场景和步骤中去进行测评。
一般来说,图片中的文字要被精准地翻译出来,需要至少具备三种能力:
第一步:火眼金睛,“看得准”。
图片翻译想要满足用户需求,首先考验的不是 NLP 技术,而是 OCR 能力。只有识别得准,才能为后续翻译奠定基础,这一能力的关键考核指标,就是字准率。
从操作上来看,苹果 iOS15 采用内置方式,可以直接选择照片中要翻译的文本,查看翻译结果;有道词典需要打开 App 中的拍照识别功能。前者在使用上要更方便一些。不过到了识别环节,iOS15 就有些拉胯了。
我们找了一个英文短句、一个英文长句和一个中文长句。结果显示,在英文字准率上,苹果和有道差距不大。
比如,有道 100% 识别出了原文“Do me a favor, can you look for my credit card.I don't find it.”
iOS15 的结果是:Do me a favor.,can you look for my credit card,I don find it.
尽管苹果将 don't 识别成了 don,但不太影响阅读,准确率还是可以接受的。
换个英文长句测试一下,下面这张图片,有道的识别结果是:
One bad chapter doesn't mean my story is over until you find a new chapter which you think it's right,达到了 98.96% 的字准率。

iOS15 的结果是:
One bad chapter t mean my story is over until you find chapter which you think it’l S right。
将 it's right 识别成了 it'l S right,可能会影响后续的语义理解。
到了中文字准率测试,有道和苹果就拉开差距了。比如下面这张图片:

有道是 100% 完整识别,苹果 iOS15 则将“雨水”的雨,“一系列”的一,没有识别出来,倒数第二段的“纪念祖”三个字也被遗漏了,直接影响阅读体验和用户理解。

综合来说,英文字准率二者差距不大,有道略胜一筹;中文字准率上,有道能做到 90% 以上的精准识别,苹果 iOS15 只有 79%,有道优势明显。
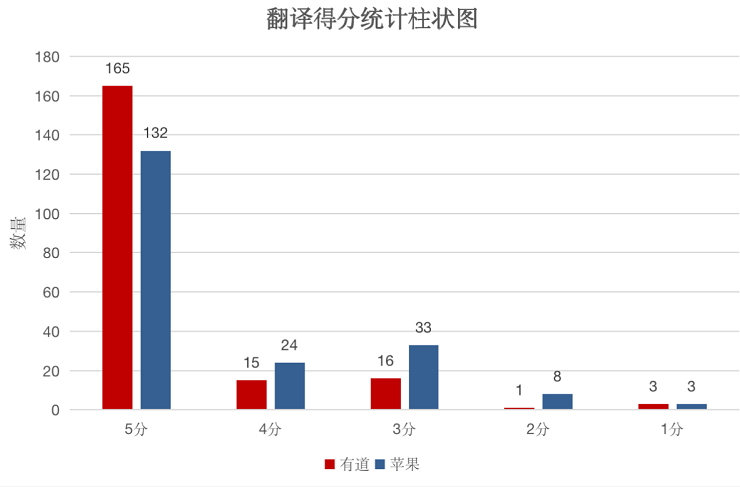
造成这一差距的原因,可能是有道词典在图片翻译上积累更多。
早在 5 年前有道就开始尝试开发图片翻译功能,后续又通过有道智云为许多主流手机厂商提供相关能力,许多用户会在各种光照条件、各种用法下使用,因此积累了大量训练语料,通过不断迭代段落分析、图片检测、图像偏移角度检测、语种检测等算法,OCR 能力自然能得到针对性优化。
加上有道作为中国公司,对中文母语的理解更深,而苹果 iOS15 刚刚开始广泛推广,在现实场景下的中文识别还有不足,也是可以理解的。
第二步:心如明镜,“搞得懂”。
图片文本识别完成后,就需要神经机器翻译来将其转化成相应的译文。中英文都是语料相对丰富的语种,因此对其理解能力的要求也更高。
所以我们选择了两个比较细节的点来考察:
一是时态。
原文“是的,今天出去玩”,含有计划的意思。
有道翻译为“Yes.we're going out today”;
苹果的译文是:Yes.go out today.
显然,有道采用了“be going”一般将来时,更准确地理解了原文的意图,表达出了计划、安排、打算做某事的意思,苹果的译文则没能体现出计划的状态。
二是单复数。
英文单词的单复数常常承担着截然不同的释义,如果无法准确识别可能会让译文与原意南辕北辙。
比如这个“1200 square”,有道词典翻译为“1200 平方”,苹果 iOS15 的翻译是“1200 个广场”。
square 在单数状态下指的是平方单位,苹果的译法很容易让读者产生歧义。
当然,在整体理解上,有道和苹果的中英互译水平都能满足基本的阅读需求。
比如这个长句:
He puts down $20,000 as a deposit on the beautiful $200,000 villa believing that his investment would increase over time.
有道的译文:他为价值 20 万美元的漂亮别墅付了 2 万美元的定金,相信他的投资会随着时间的推移而增加。
iOS15 的译文:他存了 2 万美元作为这栋美丽的 20 万美元别墅的押金,相信他的投资会随着时间的推移而增加。
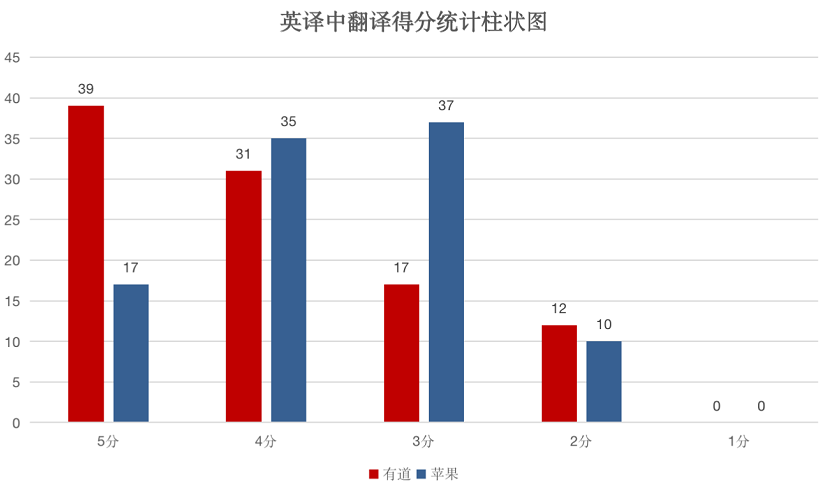
目前,图片翻译的中文互译,有道和 iOS15 基本都表现出了较强的理解能力。对一些单词用法、表达习惯上的细节洞察有差距,这背后还是语料积累、模型选择、性能优化等的差异。
第三步:舌灿莲花,“说人话”。
中文翻译,很多人的黄金指标就是“信达雅”,指的是译文要准确,不偏离原文;要通顺,语法结构符合习惯;还要优雅,用语地道而富含文采。
神经机器翻译发展到今天,能否满足这一要求呢?有道和苹果这两个带有不同语言基因的翻译平台,恰好可以调戏一番。
先来一道送分题:
原文:你们收了我 80 块;
有道译文:You charged me 580;
iOS15 译文:You received me 80 yuan。
“收钱”是用 charge,有道翻译更符合英文表达,苹果将“收到”直接翻译为 receive,不够地道。
再来一道中长句试试:
原文:After the accident,I felt myself another person。
有道译文:事故发生后,我觉得自己变了一个人;
iOS15 译文:事故发生后,我觉得自己是另一个人。
苹果将“another person”直接翻译为“另一个人”,而不是表达心态的转变,容易产生歧义,有道译作“变了一个人”,更准确和口语化。
当然,过于直译的问题有道也会犯。比如下面图片中,原文:In conclusion, drawing on the electronic media or printed books might be a good approach to understand different places or countries。
有道译为:总之,利用电子媒体或印刷书籍可能是一个很好的方法来了解不同的地方或国家;
苹果译为:总之,利用电子媒体或印刷书籍可能是了解不同地方或国家的好方法。
iOS15 对语序进行调整之后,表达更妥帖自然,有道则出现了按照对应模式直译的情况。

不过,这次测试题主要是基于生活旅游、文化交流场景来进行的,对于专有名词的翻译效果如何,还有待进一步考察。
另外,由于苹果 iOS15 在第一步 OCR 识别上字准率较低,这会直接影响后续的文本理解,因此苹果的部分翻译结果数据不具有参考性,对其翻译水平不能妄下定论。
评测可以看出,一次信达雅的图片翻译,依靠的是多技术的融合,需要 OCR、分词、语义理解、上下文记忆、主题抽取等多种能力共同发力。
因此,初出茅庐的苹果系统级图片翻译,想要取代专业翻译软件,路还很长。不过,有道也存在一些机器翻译的普遍问题,作为专业的翻译软件,仍可以继续强化其专业壁垒。
这也引发了我们的思考,为什么有了 AI,神经机器翻译依然无法媲美人类译者?
理想与现实的参差:戴着镣铐跳舞的神经机器翻译
神经网络刚被引入机器翻译时,被视为所向披靡的神器。但几年过去了,这一神奇技术确实比传统的统计机器翻译优秀很多,但距离人类翻译家的水平还有差距。
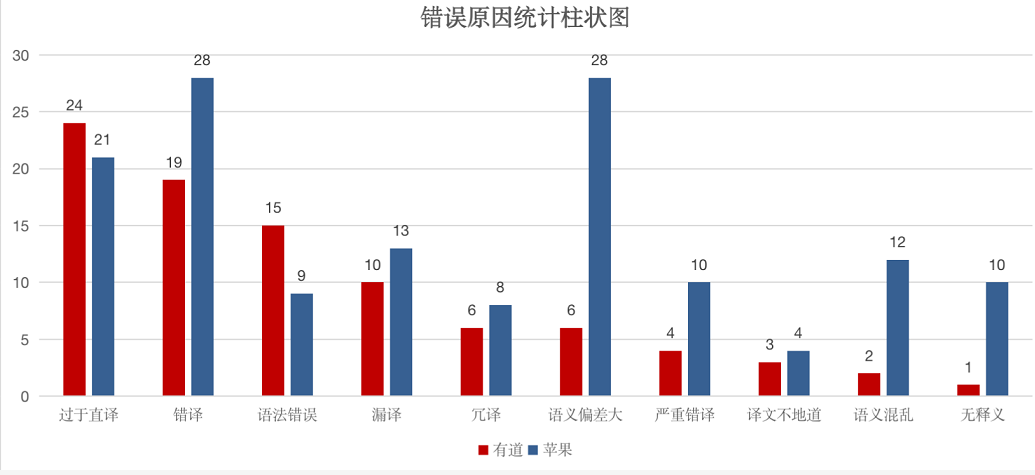
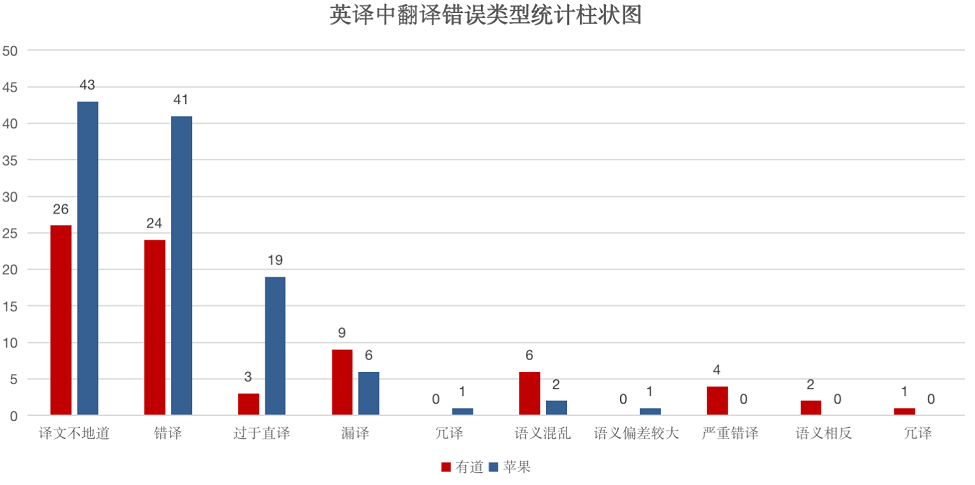
就拿这次苹果 iOS15 与有道词典的横向测评来说,二者或多或少都有不足之处。简单来说,原因可能出在几个方面:
1.OOV (Out of Vocabulary) 问题难以解决。
基于深度神经网络的机器翻译模型需要海量数据的学习。如果数据量比较小,出现次数极少的词的词向量质量就会比较低,在实际应用中出现太多未登录词,会导致错译、漏译等情况。目前,一些垂直领域资料稀少、语料不足,尤其是中文有几千上万个字符,其中很多是生僻字,这些都会影响模型表现及译文的质量。
要解决这一点,只能靠“笨功夫”积累数据。据有道词典的技术人员表示,要做好中文识别没有特别好的办法,只能不断的积累数据,迭代算法,有道在过去几年做了大量工作。
2. 算法优化与创新等待突破。
不同语言文化的文字表达、逻辑结构、信息冗余度、语法结构都不同,存在大量“信息不对称”,在“编解码“过程中出现错译也就不足为奇了。

《文化翻译论纲》一书中提到,译文等于“原文 + 原文化背景 + 译文 + 译文文化背景 + 原作者的气质和风格 + 译者的气质和风格”的混合体。
而要理解背后的文化、气质、风格等“隐藏属性”,只能通过技术迭代和创新来实现。比如有道允许用户提供额外的自定义词典,来精准调整神经网络机器翻译的局部结果,解决专有名词的翻译难题;
业内也开始尝试引入多模态翻译,通过图片中其他事物的特征来辅助理解文本。举个例子,如果机器翻译只看到 GATE 这个词,可能会把它简单的翻译成“门”,但如果图片中显示这是一张机票或者背景是飞机场,那么翻译为“登机口”就会更恰当。
3. 细分场景适配没有捷径。
随着机器翻译的普及,用户对翻译质量提出了更细分的要求,比如图片翻译时前置环节的少量识别错误可能带来的级联问题;网页翻译时不仅要提供正确的翻译,还要尽可能保持原有网页样式的一致性;文档翻译时,人名、地名、组织机构名或专业术语可能多次出现,上下文如何保持一致;在配置较低的端侧设备上,也要提供又快又好地翻译体验…… 不同场景下的各种问题,需要针对性地优化。
就拿图片翻译来说,自然场景下的图像识别十分复杂,往往在实验室中效果很好,但用户会在各种光照条件下,拍各种稀奇古怪的东西,识别完以后还需要判断哪些词属于一个句子,哪些句子是一个段落,翻译出来的结果应该如何呈现。据了解,有道也优化了很久,在算法侧对翻译模型做了鲁棒性增强,即便在实际环境中遇到个别无法避免的文字识别错误,仍然有稳定的性能表现。
从这个角度来说,图片翻译等新应用场景想要给用户带来体验的颠覆式改变,需要的不仅仅是实验室中的创新,还要关注并解决技术在应用场景中落地遇到的具体问题,来优化最终体验,没有捷径可走。

从被人类译者惊呼抢饭碗的“妖术”,到阅读学习娱乐场景中频繁出没的日常应用,神经机器翻译技术落地现实的速度超出了很多人的想象。
对于这些致用型技术来说,应用突破比理论突破要更简单,也更急迫。这也是我们在此时想聊聊图片翻译这个“小”功能的原因。
随着全球往来的逐步重启,以更自然实时的方式了解跨语种资讯越来越成为一种必然。图片翻译对于旅游出行、专业阅读、无障碍人士触网等都有着不可或缺的价值。这也是苹果、有道等产业界力量的价值所在,通过来自现实环境的数据、互动与反馈,不断迭代并推动神经机器翻译的点滴进步。
目前看来,苹果 iOS15 的系统级图片翻译要取代专业翻译软件还为时尚早,事实上可以预见,未来两者并不会相互替代,而是在各自适用的场景和不同需求强度下,相互补充,各擅所长。
来自产业界的每一次实践,都推动着技术向前一步。积沙成塔,终有一天,人类能翻越阻碍语言交流的“通天塔”。



